8 de novembro de 2021Insights de especialistas
O valor real da análise de dispositivos - A metodologia secreta da JuicyScore

Com o desenvolvimento de serviços online e o surgimento de inúmeros produtos financeiros no mercado, o número de empresas preparadas para prestar esses serviços também aumenta drasticamente a cada ano. Os líderes do setor dão alta prioridade aos parâmetros e características do produto, à experiência do cliente, à expansão da base de clientes e à fidelização dos clientes leais. O outro lado desse processo é a complexidade crescente da avaliação de risco de clientes por canais online, bem como uma proporção considerável de usuários de alto risco, que às vezes podem acessar o site de uma instituição financeira com intenções maliciosas. Assim, as empresas precisam destinar uma parcela significativa de recursos (coleta de dados, tecnologia, pessoal) para reduzir riscos e detectar usuários fraudulentos.
Junto com o desenvolvimento das empresas que atuam online, um grande número de diferentes fornecedores entrou no mercado. Eles fornecem soluções projetadas para a redução do risco de fraude. Muitas dessas soluções fornecem um conjunto de indicadores de risco (risk markers) que podem ser usados para bloquear alguns tipos de solicitações no fluxo de aplicações. No entanto, essa abordagem tem várias falhas.
A equipe JuicyScore acredita que, além de fornecer os próprios indicadores, também é necessário dar grande atenção ao valor informacional e à metodologia de uso dos dados no processo de avaliação de risco. Desenvolvemos uma série de metodologias e abordagens que nos permitem não apenas identificar segmentos de alto risco, mas também realizar a segmentação e a avaliação de risco em todo o fluxo de aplicações. Hoje, forneceremos informações detalhadas sobre uma dessas abordagens.
No nosso caso, examinamos a abordagem de prevenção à fraude baseada nas características do dispositivo.
Esta metodologia é baseada em um grande foco no dispositivo - autenticação precisa e exata, identificando os vários parâmetros que caracterizam o dispositivo, seu ambiente e como ele é usado. Mas por que damos tanta atenção ao dispositivo em si?
Se representarmos todo o espaço de probabilidade como uma projeção de dispositivos, podemos distinguir as seguintes categorias, que cobrem 4 tipos de dispositivos. São eles: dispositivos físicos, dispositivos virtuais (máquinas virtuais), dispositivos físicos com randomização e dispositivos virtuais com randomização. Vamos nos aprofundar nessas categorias que você pode ver na imagem abaixo.

A abordagem apresentada permite cobrir completamente todo o espaço de probabilidade do dispositivo e também especificar de forma muito minuciosa o segmento e avaliar o risco. Como podemos ver na imagem acima, os dispositivos físicos têm o risco relativo de fraude mais baixo, enquanto os dispositivos repetidos entre os físicos podem ter um risco maior. Tais dispositivos podem ser avaliados em termos de riscos de crédito e, em alguns casos, com verificação facilitada. Dispositivos virtuais são altamente arriscados e, portanto, verificação/validação adicional deve ser realizada. Dispositivos com randomização são os mais perigosos em termos de risco e recomendamos negar tais solicitações.
A simplicidade aparente na superfície talvez seja menor se nos aprofundarmos em tecnologias sofisticadas. Em primeiro lugar, não há um único dispositivo além dos segmentos mencionados acima. Portanto, essa abordagem nos permite capturar todo o cenário. Em segundo lugar, essa abordagem pode ser caracterizada como realmente sustentável e de alta eficácia, validada por nossa experiência de trabalho em mais de 20 países em todo o mundo.
Variáveis de índice são uma parte essencial dos atributos do vetor de dados da JuicyScore. Damos grande atenção a elas em um de nossos artigos anteriores - Deep Machine Learning: no caminho para a verdade. Mas como exatamente podemos avaliar o risco usando os dados da JuicyScore? Para entender melhor a essência tecnológica da nossa abordagem, precisamos olhar para algumas variáveis (ou variáveis do tipo IDX em nosso vetor de dados padrão), que criamos usando os algoritmos de aprendizado de máquina profundo (deep machine learning).
IDX1 é uma combinação de 50+ eventos raros, que mostram alta probabilidade de fraude por meio de manipulação técnica do dispositivo. Esta variável inclui toda a variedade de ferramentas de randomização de dispositivos, técnicas de interferência na "impressão digital digital" (digital fingerprint), bem como determina os marcadores mais perigosos de comportamento de alto risco do usuário e marcadores de conexão de rede. A variável pode ser usada tanto em regras quanto como componente de um modelo de prevenção à fraude para identificar os segmentos de clientes mais perigosos. O nível de risco aumenta junto com o valor do parâmetro; valores altos podem ser usados como filtros para negação automática.
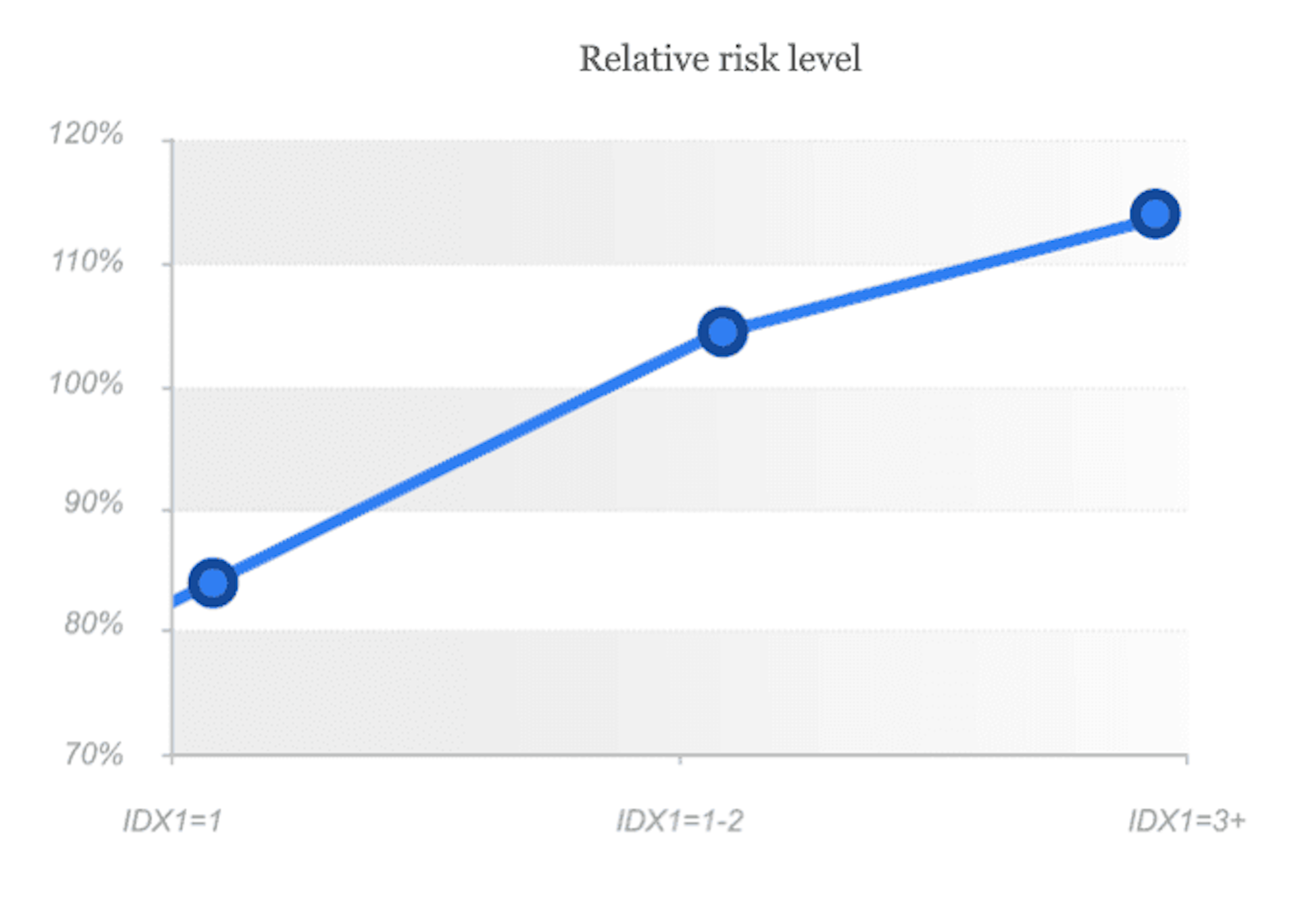
Como podemos ver no gráfico, o indicador de variabilidade 0 significa baixo risco, 1 - risco médio, quando verificação/validação adicional deve ser realizada, indicador 2+ significa alto nível de risco e, nesses casos, recomendamos negar tais aplicações.
Além do uso de randomizadores, que são identificados com o IDX1, bem como com os fatores de parada separados - por exemplo, cópia da sessão de outro dispositivo (variável do vetor session clone), identificação de anomalias no cabeçalho da sessão web (variável do vetor UserAgent Issue), indicação de manipulação com a paleta de cores (variável Canvas blocker) - também deve-se dar grande atenção a anomalias do navegador ou do sistema operacional.
IDX3 é uma combinação de marcadores de risco secundários e anomalias do dispositivo, onde cada anomalia individual pode refletir um risco possível, que deve ser levado em consideração durante a verificação do mutuário. A combinação de tais marcadores destaca um segmento de alto risco. Da mesma forma que o IDX1, o nível de risco aumenta junto com o valor da variável, e valores altos podem ser usados para negação automática.
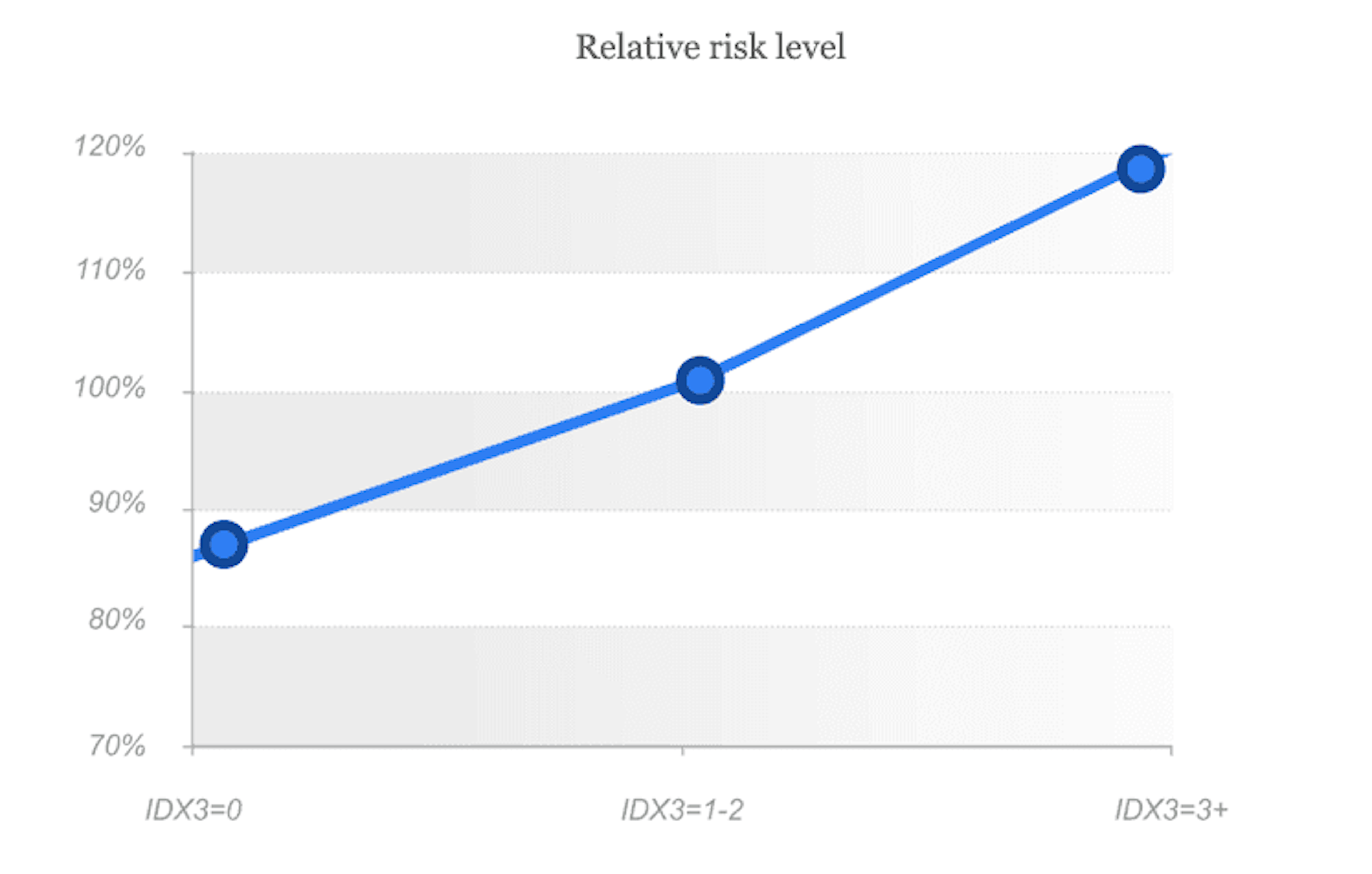
Como podemos ver no gráfico, o indicador de variabilidade 0 significa baixo risco, 1 - risco médio, quando verificação/validação adicional deve ser realizada, indicador 2+ significa alto nível de risco e, nesses casos, recomendamos negar tais aplicações.
A tabulação cruzada (cross-tabulation) de vários valores de índices também pode fornecer informações importantes sobre o nível de risco. Por exemplo, se IDX1 e IDX3 forem iguais a 0, há uma alta probabilidade de que nenhuma randomização e virtualização sejam identificadas, e estamos lidando com um dispositivo físico.
Esta é apenas uma pequena ilustração da abordagem prática das tecnologias de detecção de randomização e virtualização e seu uso na avaliação de risco e prevenção de fraudes.
Atualmente, as soluções de antifraude mais informativas e bem-sucedidas precisam atender aos requisitos comumente aceitos pelo setor:
No entanto, como todos sabemos, em antifraude e gerenciamento de risco não existe uma única abordagem universal que resolveria qualquer problema e daria 100% de resultado. A equipe JuicyScore acredita que cada nova abordagem autossustentável encontrará seu lugar.

As tecnologias modernas estão se tornando mais robustas e as medidas de segurança, mais sofisticadas. No entanto, existe uma vulnerabilidade que não pode ser corrigida por nenhum patch — a confiança humana.

Destacados del Evento JuicyScore en Mumbai: Tendencias de Fraude Digital

Deep Machine Learning: em busca da verdade
Participe de uma sessão ao vivo com nosso especialista, que mostrará como sua empresa pode identificar fraudes em tempo real.
Veja como impressões digitais únicas de dispositivos ajudam a reconhecer usuários recorrentes e a separar clientes reais de fraudadores.
Descubra as principais táticas de fraude que afetam seu mercado — e veja como bloqueá-las.
Phone:+971 50 371 9151
Email:sales@juicyscore.ai
Nossos especialistas dedicados entrarão em contato com você rapidamente.