29 de fevereiro de 2020Tecnologia
Deep Machine Learning: em busca da verdade

A informação é um recurso extremamente valioso no século XXI. A quantidade de informação na Internet aumenta a cada ano e diversos métodos são utilizados para processar esses conjuntos de dados. Hoje, vamos focar em três conceitos: inteligência artificial (IA), aprendizado de máquina (ML) e deep machine learning (DML). Ainda existe um grande número de métodos utilizados por especialistas em análise de dados, e o objetivo deste artigo não é apenas explicar as características desses conceitos, mas também mostrar exemplos bem-sucedidos de como alguns métodos podem ser aplicados para resolver problemas práticos na prevenção do risco de fraude.
Machine Learning (ML) é uma das áreas fundamentais da inteligência artificial, cuja ideia é encontrar um padrão nos dados disponíveis e, em seguida, aplicá-lo a novos objetos. Em outras palavras, é um determinado conjunto ou amostra de valores, que é usado para “treinar” o algoritmo, a fim de aplicá-lo posteriormente na resolução de vários tipos de problemas, por exemplo, previsão e classificação.
Deep Machine Learning (DML) é um subtipo do machine learning. Sua principal característica é o uso de métodos de aprendizado de máquina e redes neurais para resolver problemas reais semelhantes aos humanos. O DML busca relações intermediárias profundas entre fatores. Cada elemento da dependência encontrada deve ser verificado quanto à estabilidade e pode ser usado para resolver o problema do próximo nível - uma hierarquia específica de atributos obtidos por um ou outro algoritmo estatístico é construída no sistema, e cada nova camada contém dados sobre a anterior. Do ponto de vista prático, para resolver o problema de alto nível, é usado um ensemble de modelos, cada um deles resolvendo um dos problemas inferiores na hierarquia. Por exemplo, a tarefa de reconhecer um rosto humano pode ser uma combinação de várias tarefas: determinar os pontos do contorno do rosto, determinar as partes individuais do rosto, bem como o layout dos elementos do rosto encontrados dentro de um contorno predefinido. Outras tarefas comerciais relacionadas podem incluir detecção de fraude / spam; reconhecimento de fala / escrita; tradução e imitação de muitas outras funções cognitivas humanas.
O terceiro conceito que precisa ser esclarecido é o de evento raro ou a chamada “anomalia”. A característica básica de um evento raro não é apenas ter uma baixa frequência de ocorrência, o que segue do nome, mas também o fato de que a ocorrência de tal evento geralmente é acompanhada por consequências significativas, podendo ser positivas e, às vezes, negativas. O exemplo desse evento é um desastre natural de grande poder destrutivo. No setor financeiro, isso poderia ser um caso em que um evento leva a um alto risco de inadimplência de empréstimo ou perda em contrato de seguro.
Por um lado, é importante que as empresas sejam capazes de prever a ocorrência de tais eventos e usá-los em seus modelos para evitar o risco subsequente. Por outro lado, uma vez que eventos raros não seguem a lei da distribuição normal (que por definição requer uma amostra representativa de eventos-alvo), a modelagem de tais eventos é seriamente complicada.
Por exemplo, se projetarmos uma regressão linear em uma amostra de 500 observações, onde apenas 5 eventos-alvo estão representados (ou seja, 1% da amostra), o resultado é uma equação onde o coeficiente para uma variável independente receberá o primeiro dígito significativo apenas no quarto ou quinto dígito após a vírgula, o que torna tal modelo completamente inaplicável na prática.
Sendo uma das soluções de avaliação de risco e prevenção à fraude, a JuicyScore utiliza algoritmos de deep machine learning para desenvolver variáveis. Exemplos de tais variáveis são as variáveis de Índice (ou variáveis do tipo IDX em nosso vetor de dados padrão), que, por um lado, extraem valor de informação útil dos fatores subjacentes a esses Índices e, por outro, permitem neutralizar problemas relacionados à coleta de dados e a insuficiência de valores úteis de cada um desses fatores. Os Índices permitem usar a sinergia de muitos desses fatores que podem ser usados como variáveis separadas, refletindo as anomalias de um aspecto da conexão com a Internet, para further research.
Esclareceremos como usamos os métodos de machine learning usando uma dessas variáveis do nosso conjunto clássico de atributos de saída, nomeadamente o IDX4 - Detalhes da conexão. Este índice descreve anomalias associadas a uma conexão com a Internet, tentativas de manipular suas várias características e parâmetros. O risco dentro deste índice cresce com o valor do índice.
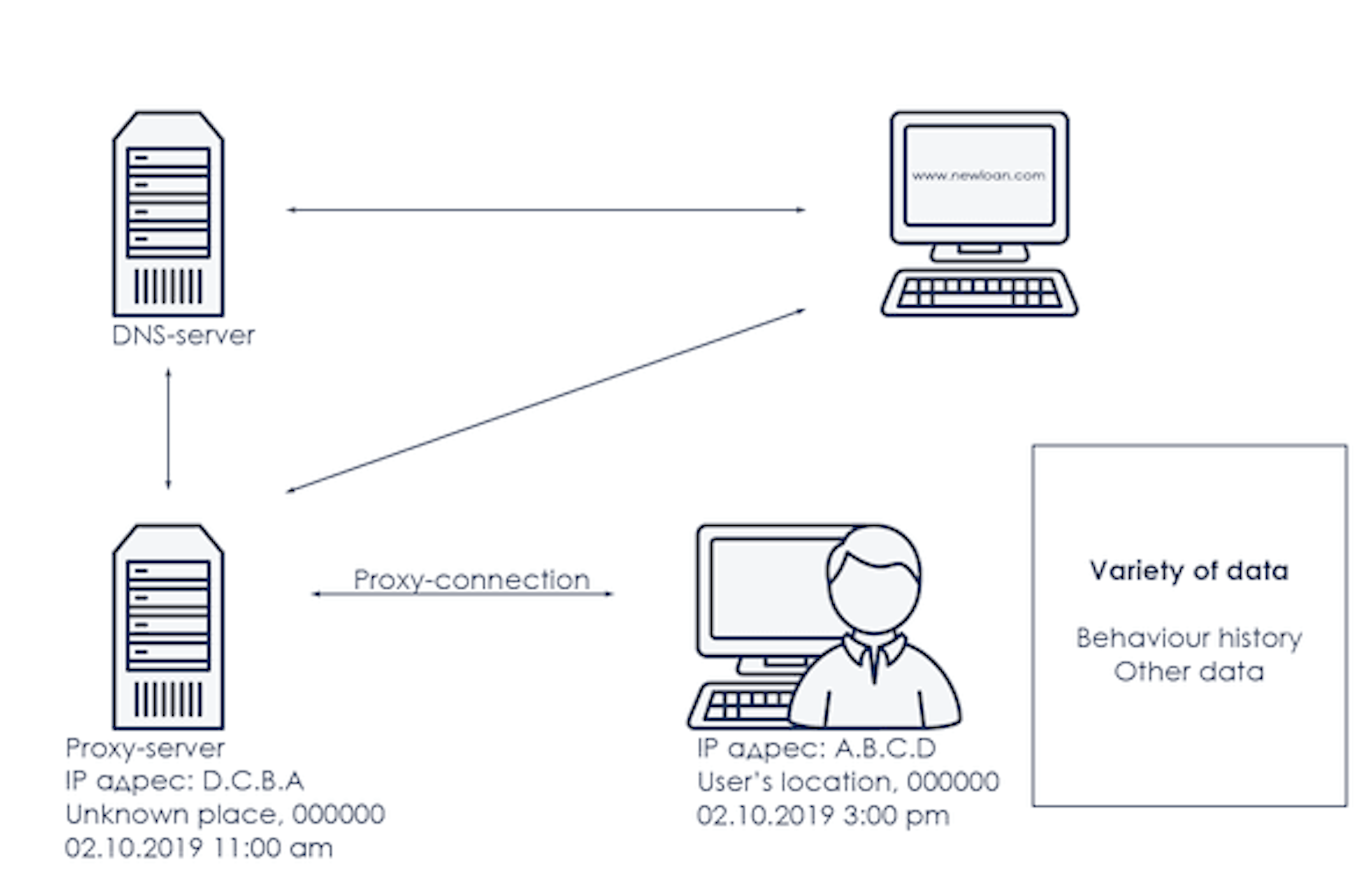
Qual é a natureza deste índice, e como exatamente os métodos de machine learning ajudaram a construir fatores dependentes e preparar esta variável? Comecemos com uma descrição da área de assunto, que está representada esquematicamente na imagem abaixo:
Há um dispositivo com o qual o usuário acessa a Internet. O dispositivo tem um endereço IP, data e hora de acesso à rede, coordenadas geográficas e endereço postal, um conjunto de dados descrevendo o comportamento do usuário e uma grande quantidade de outras informações. O dispositivo está acessando um determinado recurso web, por exemplo, o site de uma instituição financeira, o que significa que é necessário obter o endereço IP desse site, por exemplo, encontrar o servidor DNS mais próximo. O sinal para o servidor DNS pode não ir diretamente, mas, por exemplo, através de um ou mais servidores intermediários e/ou proxy. Tanto o servidor DNS quanto os servidores proxy também têm seus próprios atributos, como fuso horário, coordenadas geográficas e outro conjunto de dados.
Cada componente da área de assunto mostrada na imagem pode ser detalhado e descrito com seu próprio conjunto de atributos, parâmetros, e a principal tarefa não é apenas identificar a mecânica de ocorrência e características, mas também definir o poder preditivo e o grau de influência no evento modelado. Por exemplo, a probabilidade de inadimplência em um empréstimo. Para um entendimento mais profundo, consideraremos vários parâmetros da área de assunto descrita.
O endereço IP é um identificador único para um nó localizado na rede. Neste artigo, teremos em mente o IPv4 clássico - já consideramos os riscos e possibilidades do IPv6 anteriormente e ainda temos que estudar as possibilidades e anomalias desse tipo de endereços IP.
Uma das anomalias mais comuns associadas a um endereço IP é a incompatibilidade entre os fusos horários do dispositivo e do endereço IP. Por que a chamamos de comum? Porque, primeiro, em várias regiões do nosso planeta essa situação é usual e pode ser tratada como normal. Segundo, os fusos horários podem não coincidir por motivos objetivos, por exemplo, ao sincronizar os fusos horários do dispositivo e do endereço IP após um voo de avião, pois esse processo pode levar até um dia. Terceiro, tal discrepância é um fator de risco.
A incompatibilidade de fuso horário pode ocorrer de 0,1% dos casos, quando é uma anomalia, até 15-20%, naquelas regiões onde isso pode ser comum. De qualquer forma, a presença desse fator quase sempre indica um risco que precisa ser considerado e adicionado como um dos fatores ao motor de risco, dependendo do apetite ao risco.
Outra característica comum da conexão com a Internet é a presença de uma conexão proxy, quando por um motivo ou outro, o usuário virtual esconde sua localização ou usa uma infraestrutura de Internet não transparente. Tais eventos ocorrem de 1% na Federação Russa a dezenas de porcentagem nos países do Sudeste Asiático. Nos casos em que não há muitos desses eventos, isso geralmente indica ações deliberadas do usuário para esconder suas atividades do proprietário do recurso web, seja do credor ou de outra instituição financeira. Caso contrário, quando um número desses casos é significativo, o usuário frequentemente nem sabe como exatamente ele acessa a Internet e como a conexão de rede é construída. Do ponto de vista prático, o primeiro grupo de casos é o mais interessante, pois indica a presença de um risco pequeno ou médio, se for a única anomalia, e a presença de um alto risco, se essa anomalia for amplificada por uma série de outros fatores.
O terceiro exemplo, que em alguns casos pode ser considerado uma anomalia de conexão, são as configurações do servidor DNS. O DNS é usado para resolver todos os nomes comuns de recursos web, como www.juicyscore.com, em endereços IP. Na maioria das vezes, um host acessa o servidor DNS mais próximo ou servidores localizados próximos a ele, até que seja encontrado um servidor que tenha informações sobre qual endereço IP corresponde ao nome do recurso web inserido. Mas muitas vezes acontece que o serviço DNS mais próximo por algum motivo não é exatamente o mais próximo e pode ser separado do endereço IP real do dispositivo por fronteiras estatais e um certo número de fusos horários e centenas de quilômetros. Dependendo do país, a proporção de tais eventos também é bastante pequena, geralmente não mais que 3-5%, mas nos casos em que essa anomalia aparece, indica um nível moderado ou mesmo alto de risco, especialmente quando acompanhada por outras anomalias.
Por um lado, esses fatores são extremamente importantes devido à sua natureza e, por outro, é difícil usar tais fatores para regras de motor de crédito e automação de configurações. Agora imagine que não existem três desses fatores, mas cinco, dez ou até várias dezenas. E cada um deles é um evento raro com um grande componente de risco interno. O que fazer neste caso?
Neste caso, métodos de machine learning, tanto métodos interpretados clássicos (por exemplo, árvores de decisão ou regressão logística) quanto métodos não interpretados, podem ser usados. Na JuicyScore, preferimos usar métodos interpretados, porque, em nossa opinião, eles são mais aplicáveis à previsão de riscos financeiros e, em segundo lugar, são mais resistentes às peculiaridades dos própri dados que são usados para modelagem.
Como resultado, ao usar combinações dos métodos declarados acima, obtém-se uma variável que tem uma distribuição deste tipo.
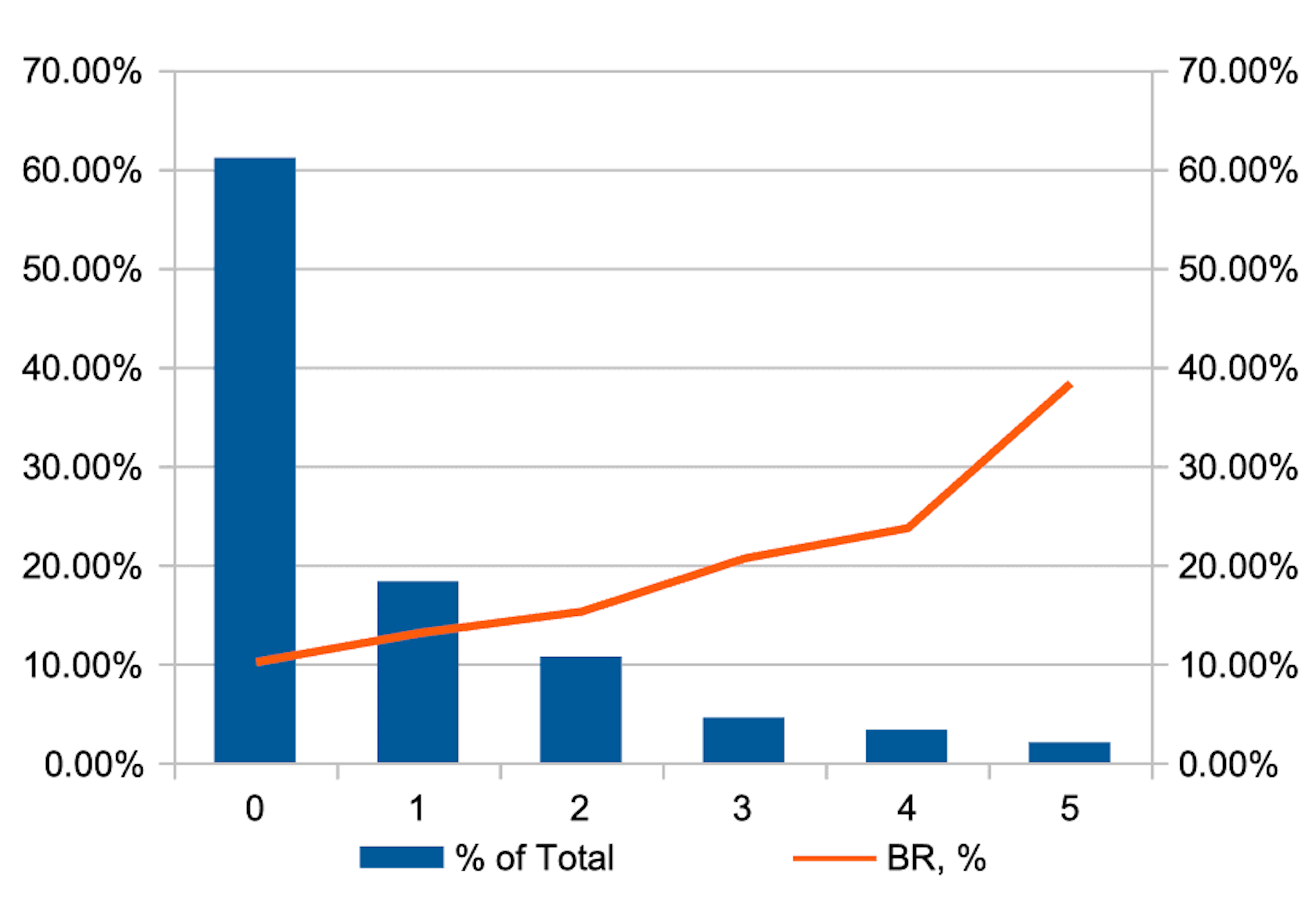
O histograma azul no gráfico mostra a distribuição da proporção de observações pelos valores da variável IDX, e a linha vermelha mostra o nível de risco relativo (BR, ou bad rate) em cada coorte.
Como pode ser visto no gráfico, usando métodos de machine learning, é possível
E assim é a distribuição dos valores do índice dependendo do país do solicitante.
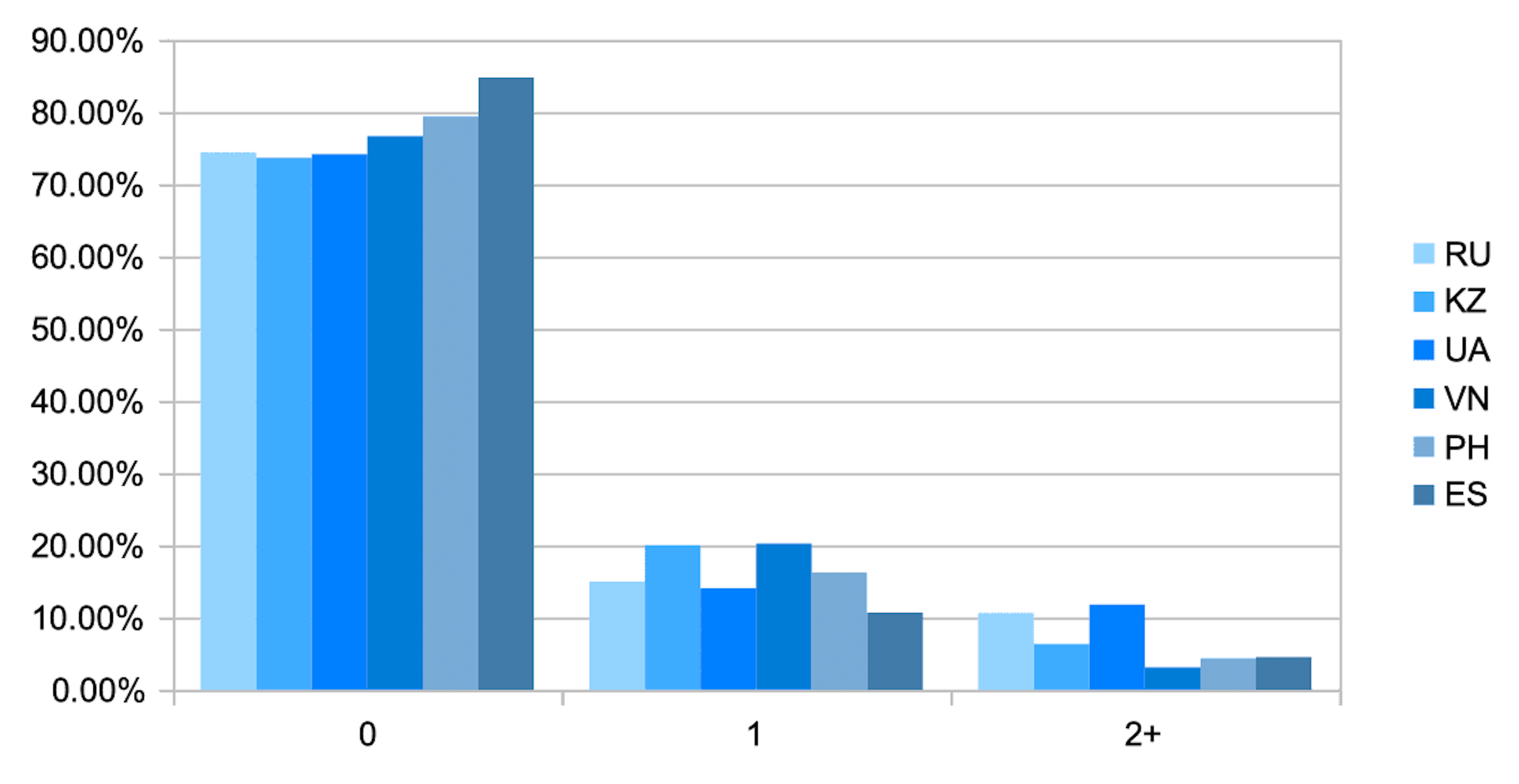
O gráfico mostra que a proporção de observações onde existem anomalias menores (coorte 1) e significativas (coorte 2+) na conexão com a Internet é altamente dependente da região. Não é surpreendente que no Vietnã, onde devido às características da infraestrutura da Internet e à falta de endereços IPv4, a participação dessas coortes seja maior do que na Espanha, onde há muito menos desses eventos, e a falta de endereços IPv4 não é sentida nessa escala. O que esses dois países têm em comum: a presença de anomalias complica a análise do dispositivo e, subsequentemente, a análise do solicitante e, portanto, aumenta a probabilidade de risco.
Os métodos de machine learning são uma ferramenta poderosa. Quando a natureza dos dados é clara, os métodos de modelagem corretos podem ser aplicados para resolver problemas, como vários tipos de previsão de risco:
Como qualquer área de assunto é um sistema complicado que pode ser descrito por um número infinito de fatores, parâmetros, métricas e atributos, o processo de extração de novos fatores e características úteis é um exercício sem fim, e o número de índices obtidos na prática é infinitamente grande, o que significa que existe a oportunidade de continuar adicionando valor de informação ao nosso serviço.

Destacados del Evento JuicyScore en Mumbai: Tendencias de Fraude Digital

As tecnologias modernas estão se tornando mais robustas e as medidas de segurança, mais sofisticadas. No entanto, existe uma vulnerabilidade que não pode ser corrigida por nenhum patch — a confiança humana.

Evolução das microfinanças: desenvolvendo um modelo de negócio eficaz
Participe de uma sessão ao vivo com nosso especialista, que mostrará como sua empresa pode identificar fraudes em tempo real.
Veja como impressões digitais únicas de dispositivos ajudam a reconhecer usuários recorrentes e a separar clientes reais de fraudadores.
Descubra as principais táticas de fraude que afetam seu mercado — e veja como bloqueá-las.
Phone:+971 50 371 9151
Email:sales@juicyscore.ai
Nossos especialistas dedicados entrarão em contato com você rapidamente.