August 17, 2024Fraud Detection
Optimizing custom anti-fraud models with JuicyScoreAI

It is often difficult for online companies to build an in-house team that not only keeps an eye on all trends in digital risk management but also applies them effectively to the company’s benefit. It becomes particularly challenging in an environment of ever-changing technology and evolving market trends, where you need to stay up-to-date with the latest innovations to be ready to adapt quickly.
For those of our clients who face difficulties in building risk management teams, we have developed JuicyScoreAI. It is a brand-new tool designed to automate the process of building custom anti-fraud scoring and selecting optimal variables. It delivers a blend of powerful analytical capabilities with an intuitive user interface, making it easy and accessible for both novice users and experienced data experts.
JuicyScoreAI's primary goal is to facilitate the efficient machine learning models’ development and deployment. The tool automates crucial steps such as data analysis and variable selection. It helps financial organizations optimize their predictive modeling efforts. It ensures more accurate estimates and leads to excellent results. Those who need rapid iteration and validation of models, allowing users to adapt to new data or changing conditions quickly, will find JuicyScoreAI extremely useful.
In simpler words, the product contains online functionality to automate custom anti fraud scoring based on the JuicyScore infrastructure. It serves to increase the general value of JuicyScore. Besides, it can be useful in case of difficulties with creating your custom antifraud model based on your existing online business infrastructure.
JuicyScoreAI was designed to meet the needs of a wide range of users. It may turn out to be an effective instrument for data analysts who need to perform rapid exploratory data analysis as well as experienced data scientists developing robust predictive models.
By integrating with existing data workflows, JuicyScoreAI will become a crucial element in any organization that relies on data-driven decision-making. For example, the finance industry relies on data drastically. JuicyScoreAI enhances the ability to extract valuable information from complex data sets. The product will help risk professionals establish simpler and faster approaches to building custom models.
Moreover, the JuicyScoreAI solution helps users quickly identify the most business-relevant variables to boost business growth. The tool can be used to compare different AI methods for assessing fraud risk and involve JuicyScore experts in consulting on ways to build custom models.
We should note that JuicyScoreAI is a complimentary product. It comes as an add-on to the already installed JuicyScore solution. An expert, responsible for risks in online business, uploads the data based on flags: a list of sessions with exposed fraudulence values for individual sessions/applications. Based on the uploaded file, JuicyScoreAI generates answers based on 10 variables or so-called IDX-indexes. Aggregated IDX variables represent a set of rare events and factors of the same nature. They are collected with the help of Deep Machine Learning algorithms forming a single variable. Later on, this variable can be used for either modeling or embedding into the decision-making system of credit organizations.
All IDX indexes were created as Gaussian variables. We did it for several reasons. First, they are subjected to statistical significance assessment/validation (meaning a classical p level of significance). Secondly, they allow us to structure the entire probability space depending on the type of fraud events. You may find more valuable insights and details on indexes in our article about rare event risk assessment. The scoring response is based on those indexes.

Building a model: an expert can select the most appropriate indexes and machine learning algorithm used to build a specific model.
Based on the 10 indexes, we get a distribution of the predictive power of each index. The main JuicyScoreAI advantage is the ability to operate client data and train on current sessions in real-time.
This is how we can pull out the benefits of index informativeness from genericScore (API v15), which represents a set of models built on IDX1-IDX10 aggregates and many auxiliary variables. The data collected during the JuicyScore or JuicyID operation is a basis. Then, the data is used to build a model. Although it is not generic or basic, it perfectly suits specific business cases. In this way, the expert has a variety of tools for model management. He gets a more basic and generic model that fits all. Besides, the model is based on company data, which makes scoring more accurate and precise.
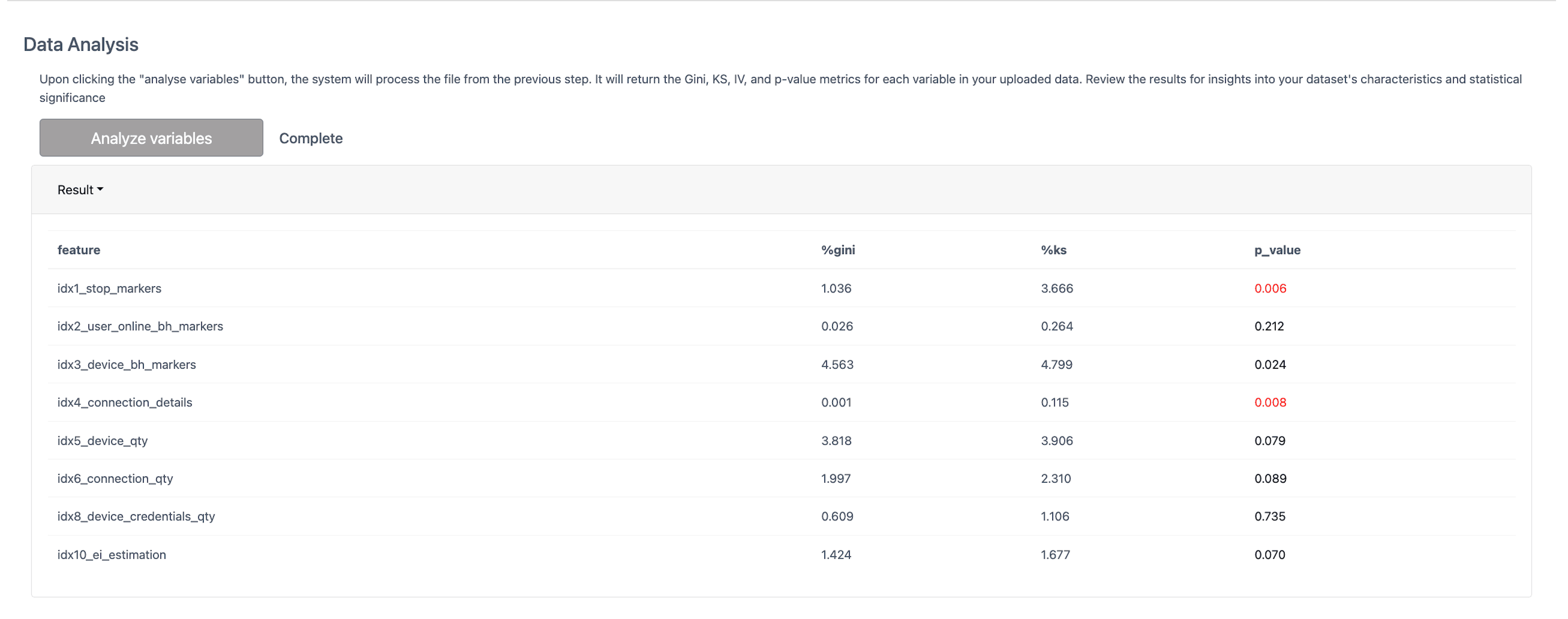
Every time an expert uploads his session data, he can overview three main metrics to assess the informativeness of the variable that can be used in a model.
The statistical index p_value is used to decipher the results of hypothesis tests. If the p_value is less than 5%, this variable is statistically significant to the target variable (predicting fraudulence session). In essence, a p_value of less than 5% recommends that this index should be added to the custom model. The criteria for incremental gini value and significance in ks statistics should be considered separately.
The IV for each index is calculated in the model information section. You can find recommendations on the most suitable indexes for forming a custom model in the personal account.
After selecting the model build type, a risk expert receives a model metric. The customization can vary depending on the business objectives. For example, if a lender needs tighter tuning and filters to exclude more applications for a safer strategy, which in particular may be required during seasonal fraud for example, during the upcoming holidays), a risk manager can configure a custom model that rejects as many borrowers with risk markers above the sample average as possible.
An expert can also customize the model with a milder rejection policy mode to increase the approval rate of applications. The JuicyScoreAI solution helps to set up an optimal model that will both increase the approval rate and also track the flow of risky applications. In addition, each model can be trained. It uses 60% of the data sampling for training and 40% for hypothesis testing and validation.
Each JuicyScoreAI feature is designed to streamline the process from data preparation to model deployment. By understanding and utilizing these features, users can enhance their predictive modeling capabilities and effectively make data-driven decisions. JuicyScoreAI supports several common data formats and provides detailed statistics for decision-making when building a model. We are convinced that our new product will be useful for online companies. It will help to strengthen their position in the modern digital landscape significantly.
Get a live session with our specialist who will show how your business can detect fraud attempts in real time.
Learn how unique device fingerprints help you link returning users and separate real customers from fraudsters.
Get insights into the main fraud tactics targeting your market — and see how to block them.
Phone:+971 50 371 9151
Email:sales@juicyscore.ai
Our dedicated experts will reach out to you promptly