29 de febrero de 2020Tecnología
Aprendizaje Automático Profundo: en el camino hacia la verdad

La información es un recurso extremadamente valioso en el siglo XXI. La cantidad de información en Internet aumenta cada año y se utilizan diversos métodos para procesar estos conjuntos de datos. Hoy nos centraremos en tres conceptos: inteligencia artificial (IA), aprendizaje automático (ML) y aprendizaje automático profundo (DML). Existe una enorme cantidad de métodos que son utilizados por especialistas y expertos en análisis de datos, y el propósito de este artículo no solo es explicar las características de estos conceptos, sino también mostrar ejemplos exitosos de cómo algunos métodos pueden aplicarse para resolver problemas prácticos y prevenir el riesgo de fraude.
El aprendizaje automático (ML) es una de las áreas fundamentales de la inteligencia artificial, cuya idea es encontrar un patrón en los datos disponibles y luego aplicarlo a nuevos objetos. En otras palabras, es un conjunto o muestra de valores que se utiliza para "entrenar" al algoritmo, con el fin de aplicarlo posteriormente para resolver diversos tipos de problemas, por ejemplo, pronósticos y clasificación.
El Aprendizaje Automático Profundo (DML) es un subtipo del aprendizaje automático. Su principal característica es el uso de métodos de aprendizaje automático y redes neuronales para resolver problemas reales similares a los humanos. El DML busca relaciones intermedias profundas entre factores. Cada elemento de la dependencia encontrada debe verificarse para determinar su estabilidad y podría utilizarse para resolver el problema del siguiente nivel: se construye en el sistema una jerarquía particular de atributos que fueron obtenidos por uno u otro algoritmo estadístico, y cada nueva capa contiene datos sobre la anterior. Desde un punto de vista práctico, para resolver el problema de nivel superior, se utiliza un conjunto de modelos, cada uno de los cuales resuelve uno de los problemas inferiores en la jerarquía. Por ejemplo, la tarea de reconocer un rostro humano podría ser una combinación de varias tareas: determinar los puntos del contorno del rostro, determinar las partes individuales del rostro, así como la disposición de los elementos del rostro encontrados dentro de un contorno predefinido. Otras tareas empresariales relacionadas pueden incluir la detección de fraude / spam; reconocimiento de voz / escritura a mano; traducción e imitación de muchas otras funciones cognitivas humanas.
El tercer concepto que debe aclararse previamente es el evento raro o la llamada "anomalía". La característica básica de un evento raro no es solo que tiene una baja frecuencia de ocurrencia, lo que se deduce de su nombre, sino también el hecho de que la ocurrencia de dicho evento generalmente va acompañada de consecuencias significativas, tanto positivas como, a veces, negativas. Un ejemplo de este evento es un desastre natural de gran poder destructivo. En el ámbito de la industria financiera, podría ser un caso en el que un evento conlleva un alto riesgo de impago de un préstamo o pérdida en un contrato de seguro.
Por un lado, es importante que las empresas puedan predecir la ocurrencia de tales eventos y utilizarlos en sus modelos para evitar el riesgo subsequent. Por otro lado, dado que los eventos raros no siguen la ley de distribución normal (que por definición requiere una muestra representativa de eventos objetivo), el modelado de tales eventos se complica seriamente.
Por ejemplo, si diseñamos una regresión lineal sobre una muestra de 500 observaciones, donde solo están representados 5 eventos objetivo (es decir, el 1% de la muestra), el resultado es una ecuación donde el coeficiente para una variable independiente recibirá el primer dígito significativo recién en el cuarto o quinto dígito después del punto decimal, lo que hace que dicho modelo sea completamente inaplicable en la práctica.
Siendo una de las soluciones de evaluación de riesgos y prevención de fraude, JuicyScore utiliza algoritmos de aprendizaje automático profundo para desarrollar variables. Ejemplos de tales variables son las variables Índice (o variables de tipo IDX en nuestro vector de datos estándar), que, por un lado, extraen valor de información útil de los factores subyacentes a estos Índices y, por otro lado, permiten nivelar problemas relacionados con la recopilación de datos y la insuficiencia de valores útiles de cada uno de estos factores. Los Índices permiten utilizar la sinergia de muchos de estos factores que pueden usarse como variables separadas, reflejando las anomalías de un aspecto de la conexión a Internet, para una investigación further.
Aclararemos cómo utilizamos los métodos de aprendizaje automático utilizando una de estas variables de nuestro conjunto clásico de atributos de salida, namely IDX4 - Detalles de la conexión. Este índice describe anomalías asociadas con una conexión a Internet, intentos de manipular sus diversas características y parámetros. El riesgo dentro de este índice crece con el valor del índice.
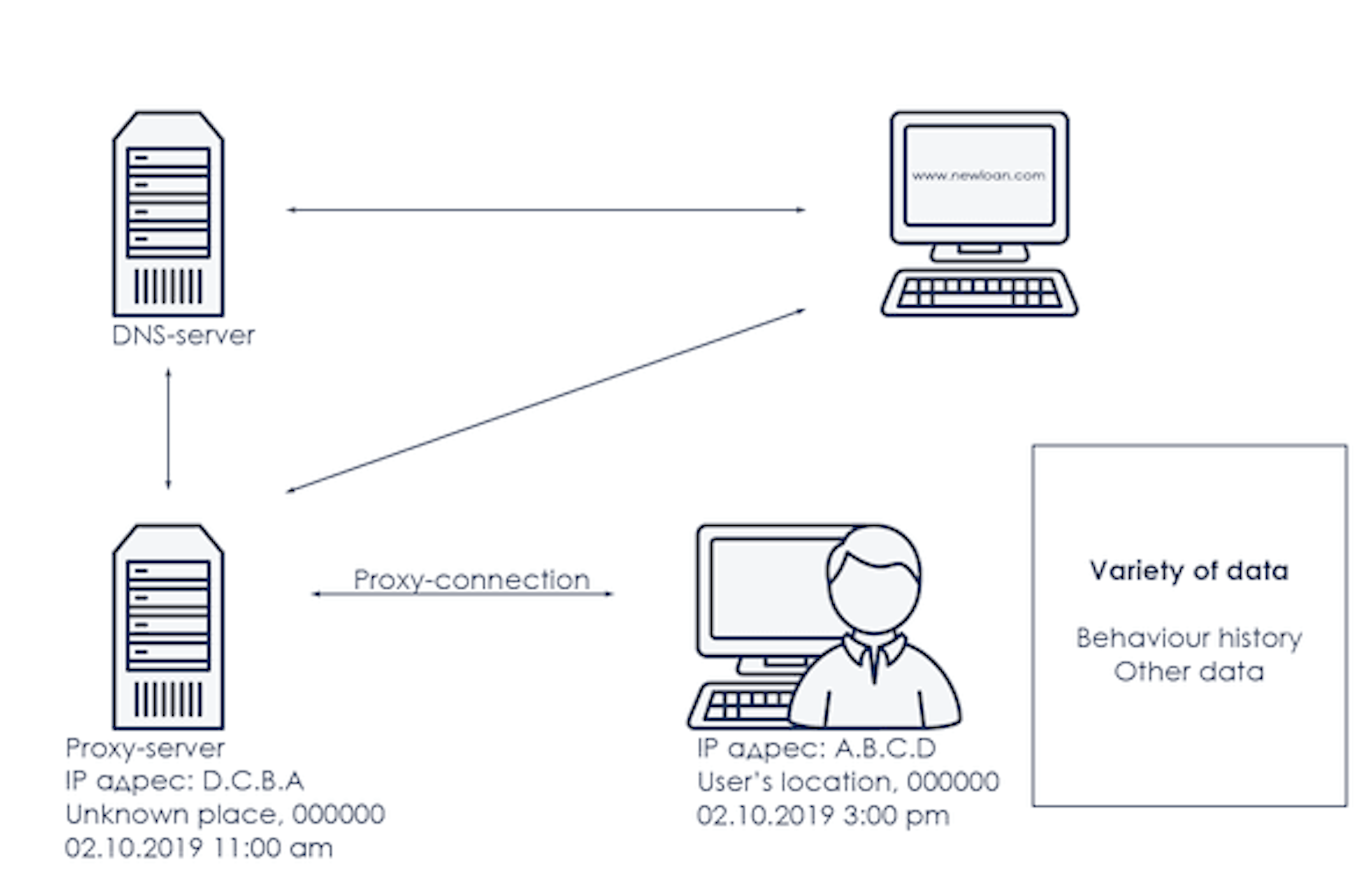
¿Cuál es la naturaleza de este índice y cómo exactamente los métodos de aprendizaje automático ayudaron a construir factores dependientes y preparar esta variable? Comencemos con una descripción del área temática, que se representa esquemáticamente en la imagen a continuación:
Existe un dispositivo con el que el usuario accede a Internet. El dispositivo tiene una dirección IP, fecha y hora de acceso a la red, coordenadas geográficas y una dirección postal, un conjunto de datos que describe el comportamiento del usuario y una gran cantidad de otra información. El dispositivo accede a un determinado recurso web, por ejemplo, el sitio web de una institución financiera, lo que significa que debe obtener la dirección IP de este sitio, por ejemplo, encontrar el servidor DNS más cercano. La señal al servidor DNS puede que no vaya directamente, sino, por ejemplo, a través de uno o más servidores intermedios y/o proxy. Tanto el servidor DNS como los servidores proxy también tienen sus propios atributos, como una zona horaria, coordenadas geográficas y otro conjunto de datos.
Cada componente del área temática mostrada en la imagen puede detallarse y describirse con su propio conjunto de atributos y parámetros, y la tarea principal no es solo identificar la mecánica de ocurrencia y las características, sino también definir el poder predictivo y el grado de influencia en el evento modelado. Por ejemplo, la probabilidad de impago de un préstamo. Para una comprensión más profunda, consideraremos varios parámetros del área temática descrita.
La dirección IP es un identificador único para un nodo ubicado en la red. En este artículo tendremos en cuenta la IPv4 clásica; ya hemos considerado los riesgos y posibilidades de IPv6 anteriormente y aún tenemos que estudiar las posibilidades y anomalías de este tipo de direcciones IP.
Una de las anomalías más comunes asociadas con una dirección IP es la falta de coincidencia entre la zona horaria del dispositivo y la de la dirección IP. ¿Por qué la llamamos común? Porque, en primer lugar, en varias regiones de nuestro planeta esta situación es habitual y puede considerarse normal. En segundo lugar, las zonas horarias pueden no coincidir por razones objetivas, por ejemplo, al sincronizar las zonas horarias del dispositivo y la zona horaria de la dirección IP después de un vuelo en avión, ya que este proceso puede tardar hasta un día. En tercer lugar, tal discrepancia es un factor de riesgo.
La falta de coincidencia de la zona horaria puede ocurrir desde el 0,1% de los casos cuando esto es una anomalía, hasta el 15-20% en aquellas regiones donde esto puede ser común. En cualquier caso, la presencia de este factor casi siempre indica un riesgo que debe tenerse en cuenta y agregarse como uno de los factores al motor de riesgo, dependiendo del apetito de riesgo.
Otra característica común de la conexión a Internet es la presencia de una conexión proxy, cuando por una u otra razón, el usuario virtual oculta su ubicación o utiliza una infraestructura de Internet no transparente. Dichos eventos ocurren desde el 1% en la Federación Rusa hasta decenas de por ciento en los países del Sudeste Asiático. En los casos en que no hay demasiados de estos eventos, esto indica con mayor frecuencia las acciones deliberadas del usuario para ocultar sus actividades al propietario del recurso web, ya sea un prestamista u otra institución financiera. De lo contrario, cuando una cantidad de tales casos es significativa, el usuario a menudo ni siquiera sabe exactamente cómo accede a Internet y cómo se construye la conexión de red. Desde un punto de vista práctico, el primer grupo de casos es el más interesante, ya que indica la presencia de un riesgo bajo o medio, si esta es la única anomalía, y la presencia de un riesgo alto, si esta anomalía se ve reforzada por una serie de otros factores.
El tercer ejemplo, que en algunos casos podría considerarse una anomalía de conexión, son la configuración del servidor DNS. DNS se utiliza para resolver todos los nombres comunes de recursos web como www.juicyscore.com en direcciones IP. La mayoría de las veces, un host accede al servidor DNS más cercano o a los servidores ubicados cerca de él, hasta que se encuentra un servidor que tiene información sobre qué dirección IP corresponde al nombre del recurso web ingresado. Pero a menudo sucede que el servicio DNS más cercano por alguna razón no es el más cercano y puede estar separado de la dirección IP real del dispositivo por fronteras estatales y una cierta cantidad de zonas horarias y cientos de kilómetros. Dependiendo del país, la proporción de tales eventos también es bastante pequeña, generalmente no más del 3-5%, pero en los casos en que aparece esta anomalía, indica un nivel de riesgo moderado o incluso alto, especialmente cuando se acompaña de otras anomalías.
Por un lado, estos factores son extremadamente importantes debido a su naturaleza y, por otro lado, es difícil utilizar dichos factores para reglas del motor de crédito y la automatización de configuraciones. Ahora imagine que no hay tres de estos factores, sino cinco, diez o incluso varias docenas. Y cada uno de ellos es un evento raro con un gran componente de riesgo interno. ¿Qué hacer en este caso?
En este caso, se pueden utilizar métodos de aprendizaje automático, tanto métodos interpretados clásicos (por ejemplo, árboles de decisión o regresión logística) como métodos no interpretados. En JuicyScore preferimos utilizar métodos interpretados porque, en primer lugar, en nuestra opinión, son más aplicables para pronosticar riesgos financieros y, en segundo lugar, son más resistentes a las peculiaridades de los datos mismos que se utilizan para el modelado.
Como resultado, al utilizar combinaciones de los métodos mencionados anteriormente, se obtiene una variable que tiene una distribución de este tipo.
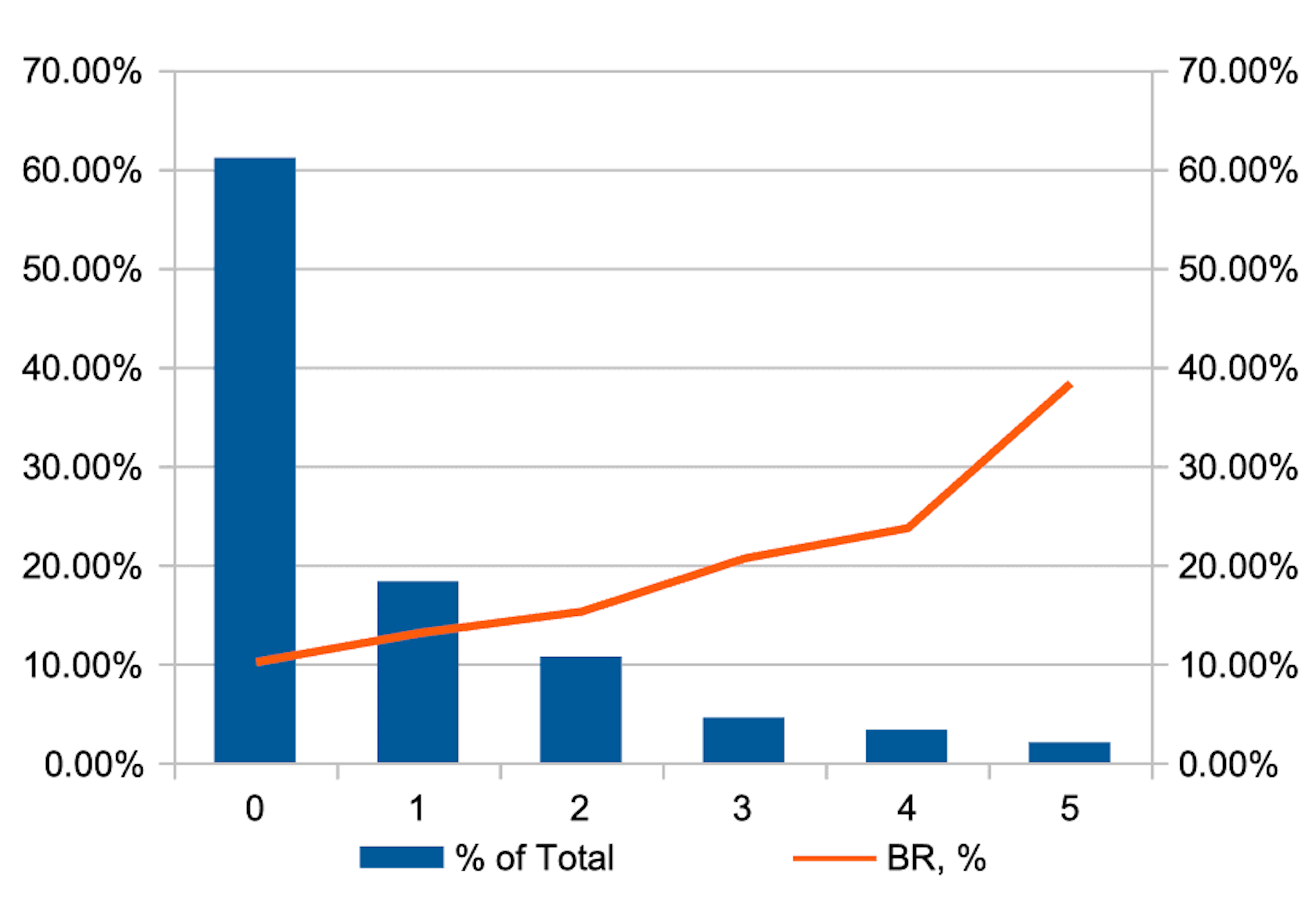
El histograma azul en el gráfico muestra la distribución de la proporción de observaciones por los valores de la variable IDX, y la línea roja muestra el nivel de riesgo relativo (BR, o tasa de malos) en cada cohorte.
Como se puede ver en el gráfico, utilizando métodos de aprendizaje automático, es posible
Y así es como se ve la distribución de los valores del índice dependiendo del país del solicitante.
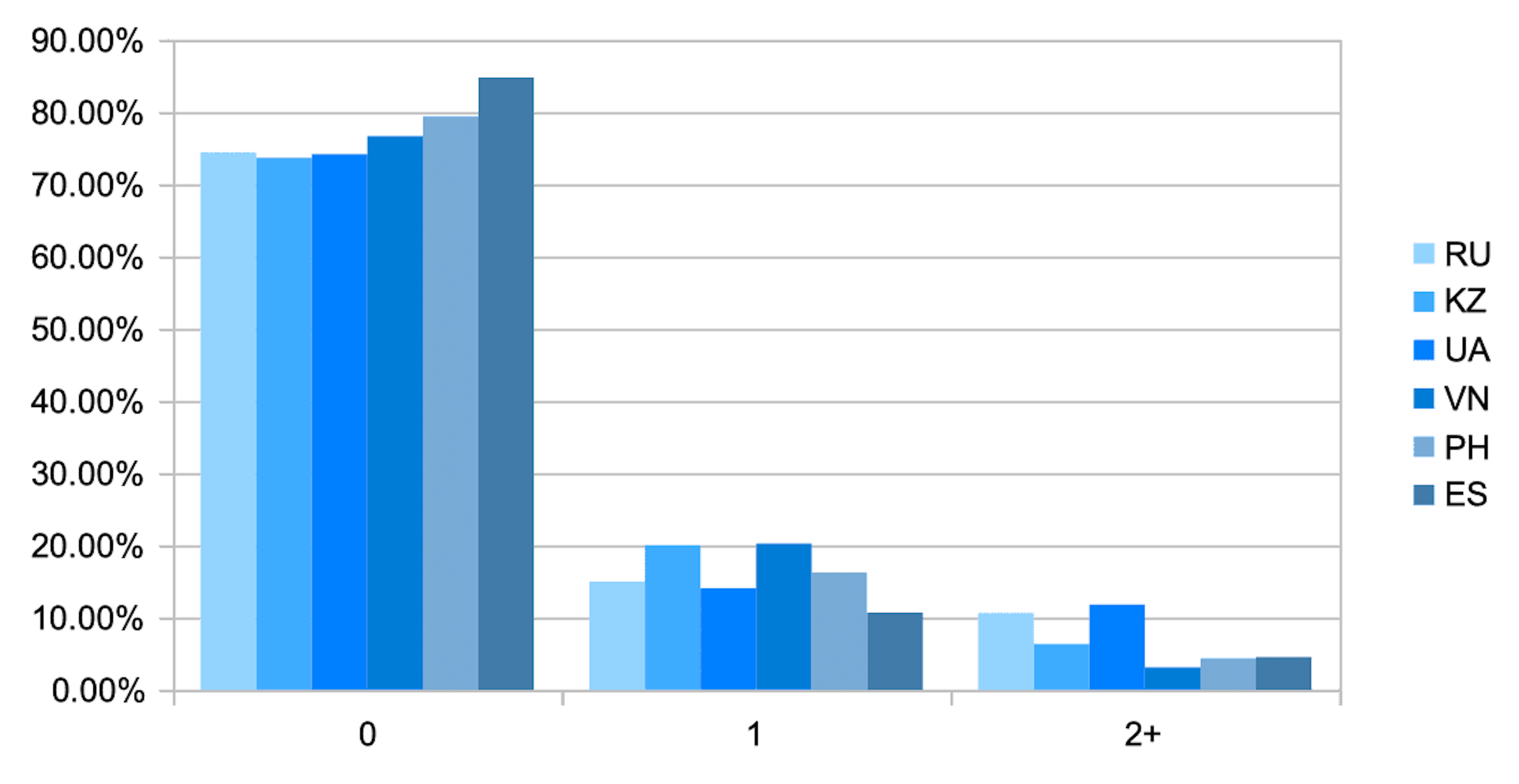
El gráfico muestra que la proporción de observaciones donde existen anomalías menores (cohorte 1) y significativas (cohorte 2+) en la conexión a Internet depende en gran medida de la región. No es sorprendente que en Vietnam, donde debido a las características de la infraestructura de Internet y la falta de direcciones IPv4, la participación de estas cohortes sea mayor que en España, donde hay muchos menos de estos eventos y la falta de direcciones IPv4 no se siente en tal escala. Lo que estos dos países tienen en común: la presencia de anomalías complica el análisis del dispositivo y, posteriormente, el análisis del solicitante, y por lo tanto aumenta la probabilidad de riesgo.
Los métodos de aprendizaje automático son una herramienta poderosa. Cuando la naturaleza de los datos es clara, se pueden aplicar los métodos de modelado correctos para resolver problemas, como varios tipos de pronóstico de riesgo:
Dado que cualquier área temática es un sistema complicado que puede describirse mediante un número infinito de factores, parámetros, métricas y atributos, el proceso de extracción de nuevos factores y características útiles es un ejercicio incesante, y el número de índices obtenidos en la práctica es infinitamente grande, lo que significa que existe la oportunidad de seguir agregando valor de información a nuestro servicio.

Mejore la eficacia de la 2FA: proteja a sus clientes

Cómo las fintech mexicanas están utilizando inteligencia de dispositivos y señales de comportamiento para detectar tráfico de alto riesgo, reducir pérdidas y escalar operaciones con mayor control desde las primeras etapas de crecimiento.

El sistema Pix de Brasil revolucionó los pagos y amplió el acceso financiero. Sin embargo, su rápido crecimiento también ha impulsado el fraude, el aumento del endeudamiento y nuevos riesgos sistémicos. Este artículo analiza las principales lecciones para el fintech global.
Reciba una sesión en directo con nuestro especialista, quien le mostrará cómo su negocio puede detectar fraudes en tiempo real.
Vea cómo las huellas únicas de los dispositivos le ayudan a vincular usuarios recurrentes y distinguir clientes reales de estafadores.
Conozca las principales tácticas de fraude en su mercado — y vea cómo puede bloquearlas.
Phone:+971 50 371 9151
Email:sales@juicyscore.ai
Nuestros expertos le contactarán a la brevedad.